Python Machine Learning Preprocessing The Data – As in real world we deal with alot of raw data. Python Machine Learning algorithms expect Data to be formatted in a certain way before they start the training Process. in order to prepare the data for ingestion by Machine Learning algorithms, we have to preprocess it and convert the Data in to right format.
You can see my before article about Python Machine Learning
Preprocessing Data Types
There are four different kinds of Preprocessing The Data
- Binarization
- Mear Removal
- Scalling
- Normalization
So now lets see an example first we need to import these lines of code
|
1 2 |
import numpy as np from sklearn import preprocessing |
After that we are going to define our data
|
1 2 3 4 |
data = np.array([[5.1, -2.9, 3.3], [-1.2, 7.8, -6.1], [3.9, 0.4, 2.1], [7.3, -9.9, -4.5]]) |
1: Binarization: So when we want to convert our numerical values to Boolean values we use Binarization process, and we have an inbuilt method in Sklearn that is called binarize(), this method takes our input value the a threshold.
Binarization Preprocessing Example
|
1 2 3 4 5 6 7 8 9 10 11 |
import numpy as np from sklearn import preprocessing data = np.array([[5.1, -2.9, 3.3], [-1.2, 7.8, -6.1], [3.9, 0.4, 2.1], [7.3, -9.9, -4.5]]) binarizedData = preprocessing.Binarizer(threshold=2.1).transform(data) print("Binarized Data",binarizedData) |
The result will be
|
1 2 3 4 |
Binarized Data [[1. 0. 1.] [0. 1. 0.] [1. 0. 0.] [1. 0. 0.]] |
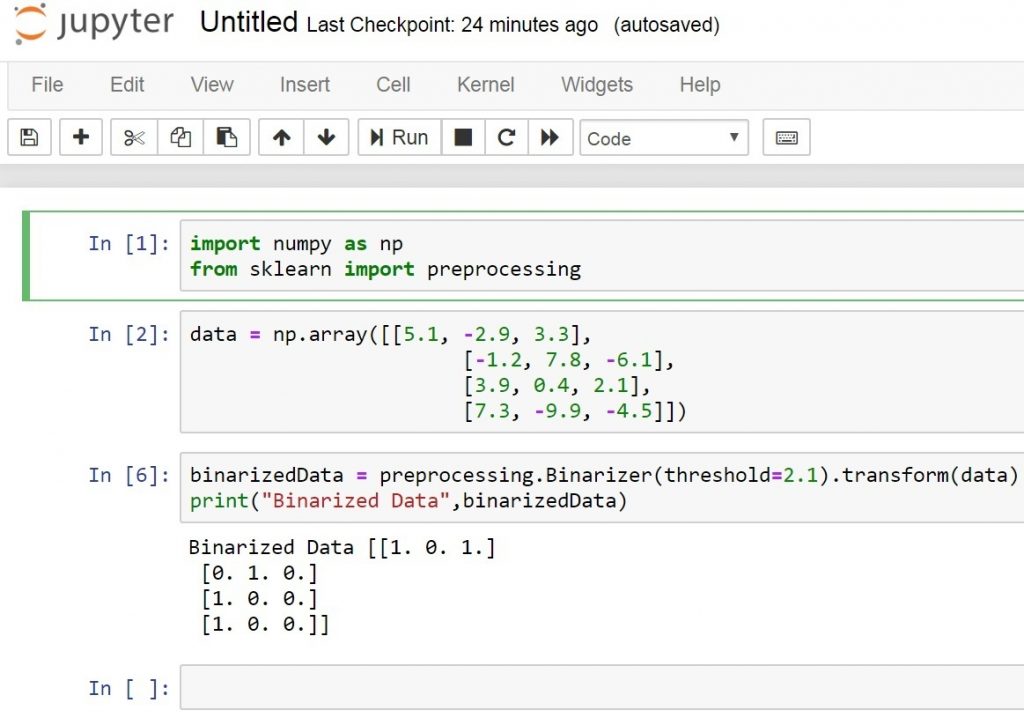
2: Mean Removal: Removing the mean is a common preprocessing technique used in machine learning. It’s usually useful to remove the mean from our feature vector, so that each feature is centered on zero. We do this in order to remove bias from the features in our feature vector.
So first lets determine the mean and standard deviation
|
1 2 3 4 5 6 7 8 9 10 11 |
import numpy as np from sklearn import preprocessing data = np.array([[5.1, -2.9, 3.3], [-1.2, 7.8, -6.1], [3.9, 0.4, 2.1], [7.3, -9.9, -4.5]]) print("Mean =", data.mean(axis=0)) print("Standard Deviation =", data.std(axis=0)) |
This will be the result
|
1 2 |
Mean = [ 3.775 -1.15 -1.3 ] Standard Deviation = [3.12039661 6.36651396 4.0620192 ] |
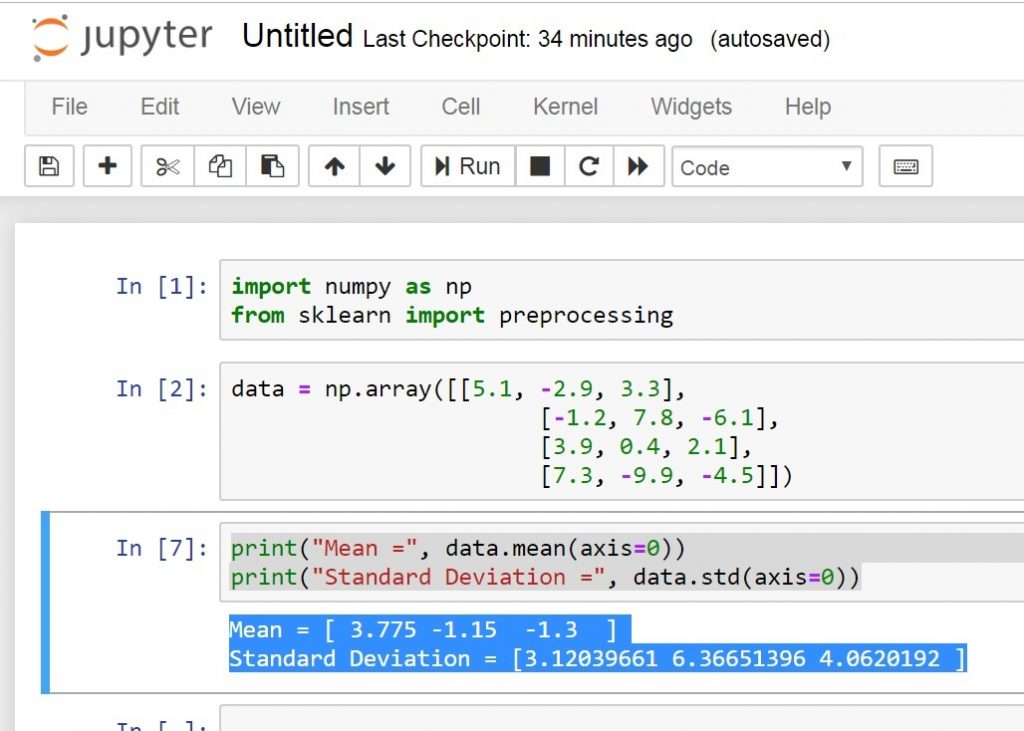
The above lines of code displays the mean and standard deviation of the input data. Let’s
remove the mean:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import numpy as np from sklearn import preprocessing data = np.array([[5.1, -2.9, 3.3], [-1.2, 7.8, -6.1], [3.9, 0.4, 2.1], [7.3, -9.9, -4.5]]) scaledData = preprocessing.scale(data) print("Mean =", scaledData.mean(axis=0)) print("Sandard Deviation =", scaledData.std(axis=0)) |
This is the result
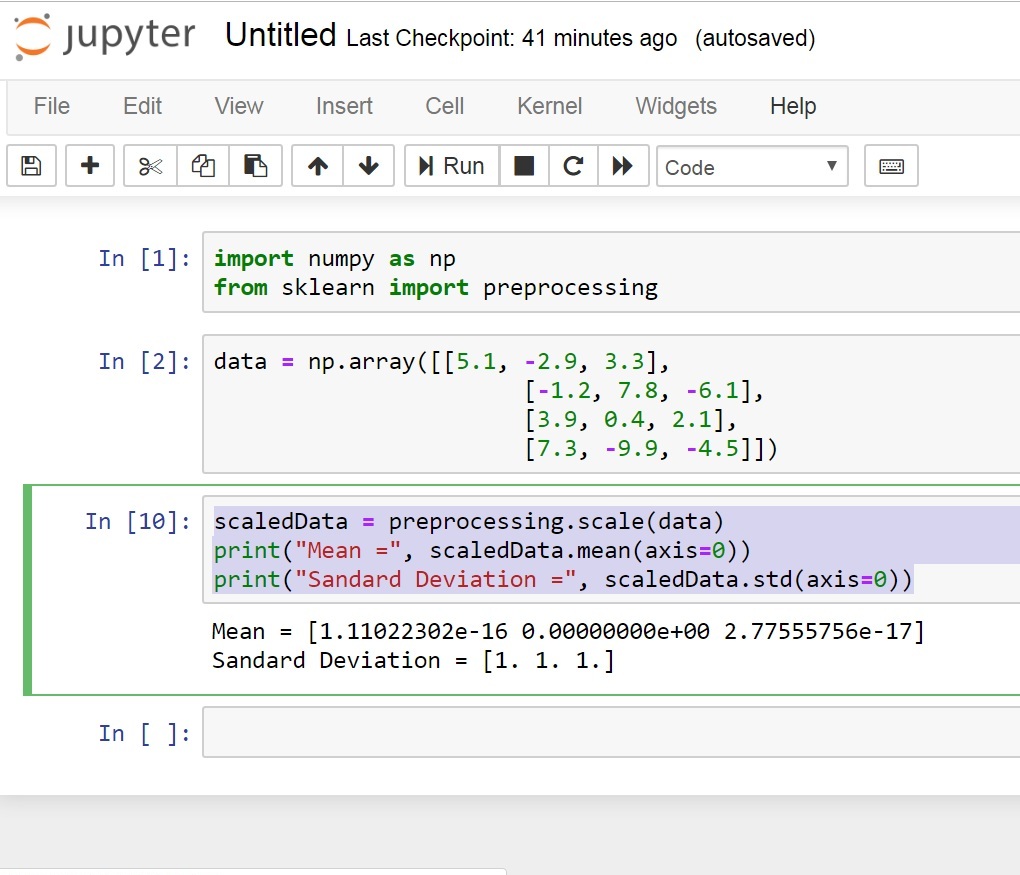
3: Scaling: In our feature vector, the value of each feature can vary between many random values. So it becomes important to scale those features so that it is a level playing field for the machine learning algorithm to train on. We don’t want any feature to be artificially large or small just because of the nature of the measurements.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import numpy as np from sklearn import preprocessing data = np.array([[5.1, -2.9, 3.3], [-1.2, 7.8, -6.1], [3.9, 0.4, 2.1], [7.3, -9.9, -4.5]]) scaler_minmax = preprocessing.MinMaxScaler(feature_range =(0,1)) scaled_minmax = scaler_minmax.fit_transform(data) print("Min Max Scaled Data", scaled_minmax) |
This is the result
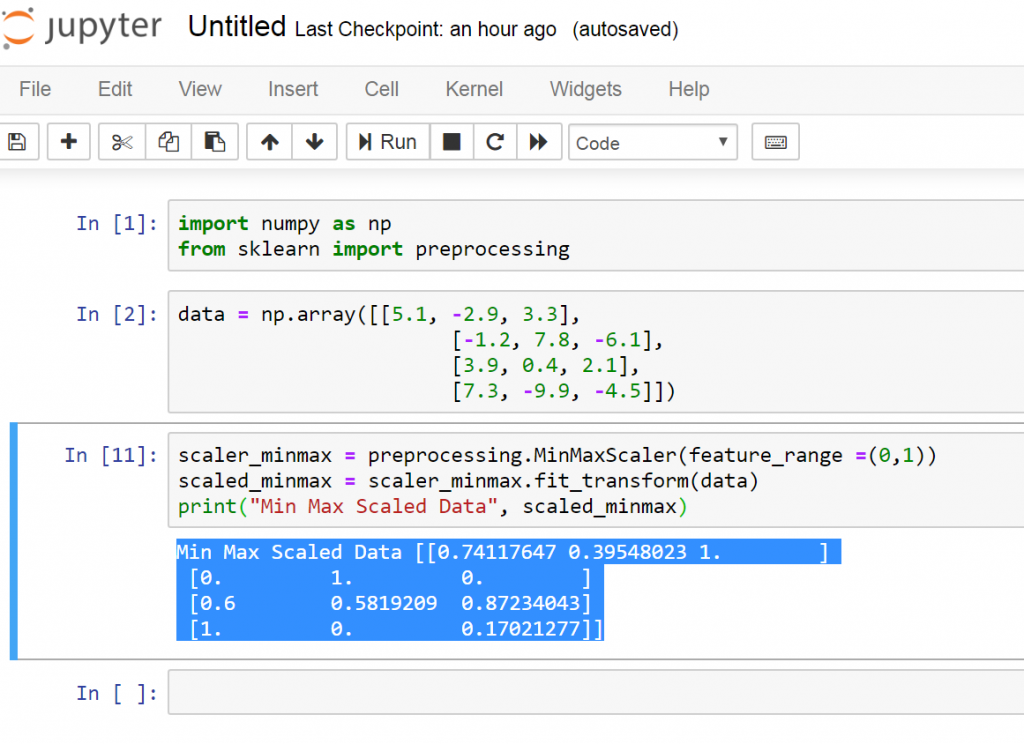
4: Normalization: We use the process of normalization to modify the values in the feature vector so that we can measure them on a common scale. In machine learning, we use many different forms of normalization.
Some of the most common forms of normalization aim to modify the values
so that they sum up to 1. L1 normalization, which refers to Least Absolute Deviations,
works by making sure that the sum of absolute values is 1 in each row. L2 normalization,
which refers to least squares, works by making sure that the sum of squares is 1.
In general, L1 normalization technique is considered more robust than L2 normalization
technique. L1 normalization technique is robust because it is resistant to outliers in the data.
A lot of times, data tends to contain outliers and we cannot do anything about it. We want
to use techniques that can safely and effectively ignore them during the calculations. If we
are solving a problem where outliers are important, then maybe L2 normalization becomes
a better choice.
This is the example for the normalization
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
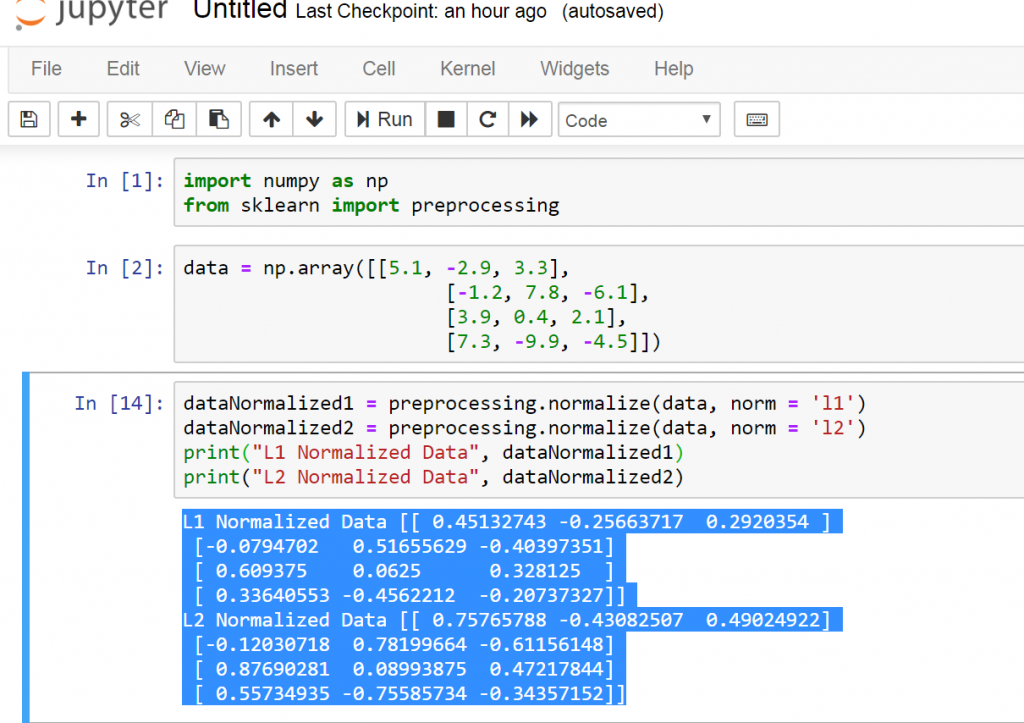
import numpy as np from sklearn import preprocessing data = np.array([[5.1, -2.9, 3.3], [-1.2, 7.8, -6.1], [3.9, 0.4, 2.1], [7.3, -9.9, -4.5]]) dataNormalized1 = preprocessing.normalize(data, norm = 'l1') dataNormalized2 = preprocessing.normalize(data, norm = 'l2') print("L1 Normalized Data", dataNormalized1) print("L2 Normalized Data", dataNormalized2) |
This is the result
FAQs:
What is preprocessing data in machine learning?
Preprocessing data in machine learning refers to the process of preparing and cleaning the raw data before feeding it into a machine learning algorithm. It involves transforming the data into a format that is suitable for analysis, removing noise, handling missing values, scaling features, encoding categorical variables and many more.
What are the 5 major steps of data preprocessing?
The five major steps of data preprocessing are:
-
- Data Cleaning: Handling missing values, removing duplicates, and dealing with outliers.
- Data Transformation: Scaling features, encoding categorical variables and transforming data types.
- Data Reduction: Reducing dimensionality through techniques like PCA (Principal Component Analysis) or feature selection.
- Data Integration: Combining data from multiple sources into a single dataset.
- Data Normalization: Normalizing or standardizing numerical features to a common scale.
How do I preprocess data in pandas Python?
You can preprocess data in pandas Python using different built-in functions and methods. Some common preprocessing tasks include:
- Handling missing values: Using methods like fillna() or dropna() to handle missing data.
- Encoding categorical variables: Using pd.get_dummies() for one-hot encoding or LabelEncoder from sklearn.preprocessing for label encoding.
- Scaling numerical features: Using methods like Min-Max scaling or Z-score normalization.
- Removing outliers: Filtering data based on statistical measures or using techniques like winsorization.
Which library is used for data preprocessing in Python?
The primary library used for data preprocessing in Python is pandas. Pandas provides powerful data manipulation and analysis tools, and this makes it ideal for handling and preprocessing structured data. Also libraries like NumPy, scikit-learn and TensorFlow also offer functionality for specific preprocessing tasks such as scaling, encoding, and handling missing values.
Subscribe and Get Free Video Courses & Articles in your Email