Python Machine Learning Label Encoding – When we do classification, there will be a lot of Labels that we are going to deal with that these Labels can be in the form of words, numbers or something else, so when we are using Sklearn it expects numbers. so if the data are numbers then there is no problem, we can use them directly to start training. But this is not usually the case. In the real world, labels are in the form of words, because words are human readable. We label our training data with words so that the mapping can be tracked. To convert word labels into numbers, we need to use a label encoder. Label encoding refers to the process of transforming the word labels into numerical form. This enables the algorithms to operate on our data.
You can read more articles on Python Machine Learning
- Python Machine Learning Introduction
- Python Machine Learning Open Source Libraries
- Python Machine Learning Preprocessing The Data
So this is the code for the Python Machine Learning Label Encoding
|
1 2 3 4 5 6 7 8 9 10 11 12 |
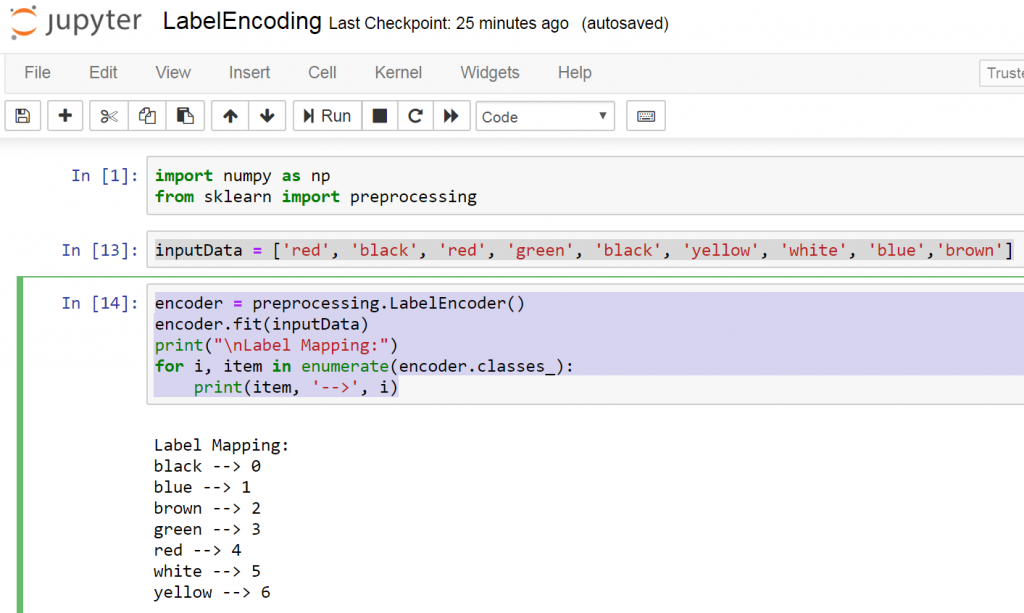
import numpy as np from sklearn import preprocessing inputData = ['red', 'black', 'red', 'green', 'black', 'yellow', 'white', 'blue','brown'] encoder = preprocessing.LabelEncoder() encoder.fit(inputData) print("nLabel Mapping:") for i, item in enumerate(encoder.classes_): print(item, '-->', i) |
These line of code are our sample data.
|
1 |
inputData = ['red', 'black', 'red', 'green', 'black', 'yellow', 'white', 'blue','brown'] |
And this is the mapping between words and numbers.
|
1 2 3 4 5 |
encoder = preprocessing.LabelEncoder() encoder.fit(inputData) print("nLabel Mapping:") for i, item in enumerate(encoder.classes_): print(item, '-->', i) |
This is the result
|
1 2 3 4 5 6 7 8 |
Label Mapping: black --> 0 blue --> 1 brown --> 2 green --> 3 red --> 4 white --> 5 yellow --> 6 |
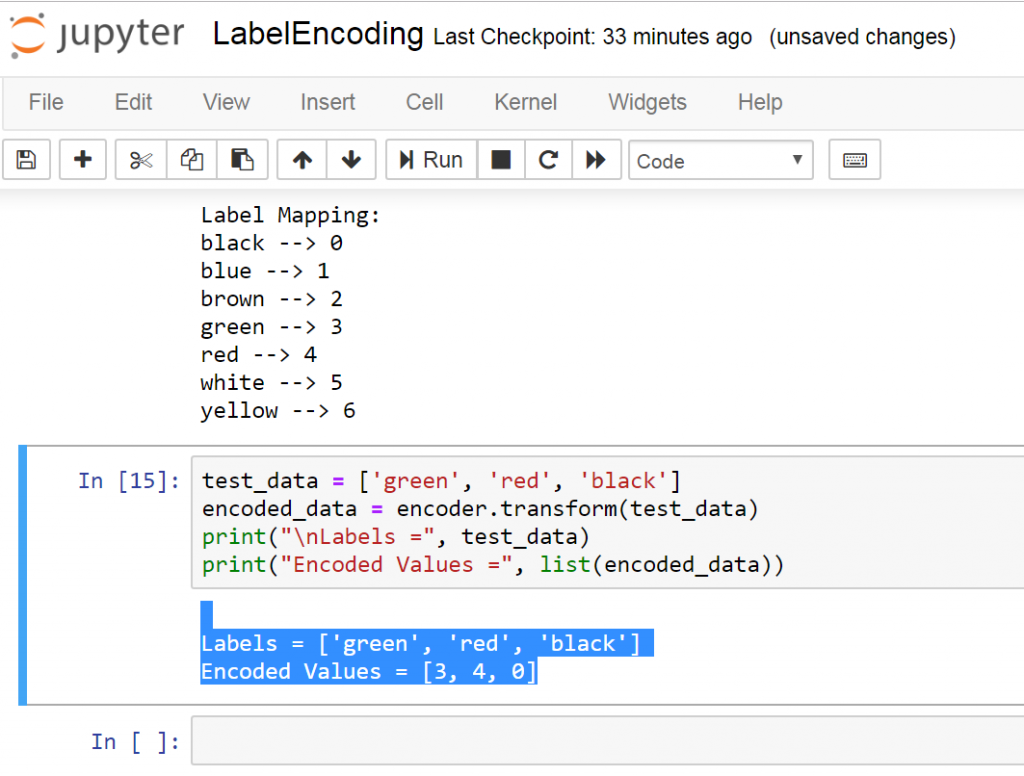
Let’s encode a set of randomly ordered labels to see how it performs.
Add these lines of codes to above code
|
1 2 3 4 |
test_data = ['green', 'red', 'black'] encoded_data = encoder.transform(test_data) print("nLabels =", test_data) print("Encoded Values =", list(encoded_data)) |
This is the result
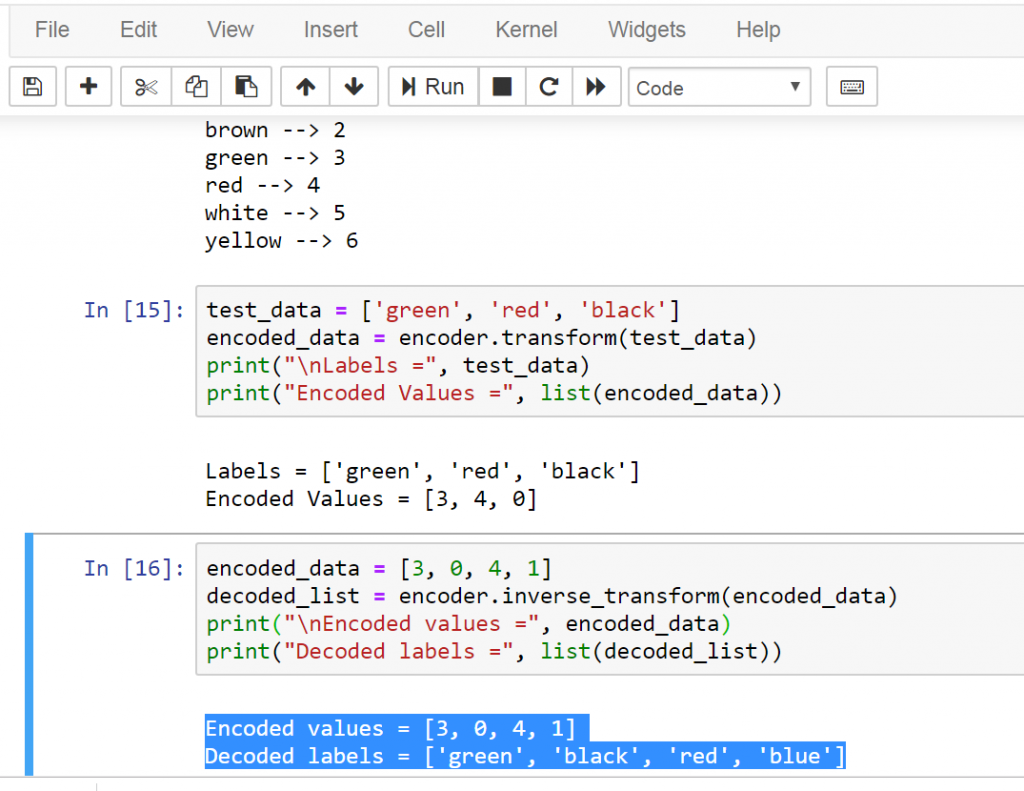
So now we are going to decode a random set of numbers.
Add these lines of codes
|
1 2 3 4 |
encoded_data = [3, 0, 4, 1] decoded_list = encoder.inverse_transform(encoded_data) print("nEncoded values =", encoded_data) print("Decoded labels =", list(decoded_list)) |
This is the result
Complete source code for this article
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import numpy as np<br>from sklearn import preprocessing inputData = ['red', 'black', 'red', 'green', 'black', 'yellow', 'white', 'blue','brown'] encoder = preprocessing.LabelEncoder()<br>encoder.fit(inputData)<br>print("nLabel Mapping:")<br>for i, item in enumerate(encoder.classes_):<br>print(item, '-->', i) test_data = ['green', 'red', 'black']<br>encoded_data = encoder.transform(test_data)<br>print("nLabels =", test_data)<br>print("Encoded Values =", list(encoded_data)) encoded_data = [3, 0, 4, 1]<br>decoded_list = encoder.inverse_transform(encoded_data)<br>print("nEncoded values =", encoded_data)<br>print("Decoded labels =", list(decoded_list)) |
FAQs:
What is label encoding in Python?
Label encoding is a technique used to convert categorical data into numerical data in Python. It assigns a unique integer to each category in the dataset. For example, if you have categories like “red,” “green,” and “blue,” label encoding would assign them integers like 0, 1, and 2.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from sklearn.preprocessing import LabelEncoder # Sample categorical data categories = ['red', 'green', 'blue', 'red', 'blue', 'green'] # Initialize LabelEncoder label_encoder = LabelEncoder() # Fit and transform the data encoded_categories = label_encoder.fit_transform(categories) # Print the original and encoded data print("Original categories:", categories) print("Encoded categories:", encoded_categories) |
How to label data for machine learning in Python?
For labeling data for machine learning in Python, you can use the LabelEncoder class from the sklearn.preprocessing module. You fit the encoder to your categorical data and after that transform it to convert the categories into numerical labels.
When to use LabelEncoder and OneHotEncoder?
- LabelEncoder: Use LabelEncoder when you have a categorical feature with ordinal relationships between categories (e.g., “low,” “medium,” “high”). It assigns a unique integer to each category, preserving the ordinality.
- OneHotEncoder: Use OneHotEncoder when you have nominal categorical features (categories with no inherent order) or when you want to avoid imposing any ordinal relationship between categories. It creates binary columns for each category, indicating its presence or absence in the original feature.
LabelEncoder Example
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from sklearn.preprocessing import LabelEncoder # Sample categorical data representing house sizes sizes = ['small', 'medium', 'large', 'medium', 'small'] # Initialize LabelEncoder label_encoder = LabelEncoder() # Fit and transform the data encoded_sizes = label_encoder.fit_transform(sizes) # Print the original and encoded data print("Original sizes:", sizes) print("Encoded sizes:", encoded_sizes) |
OneHotEncoder Example
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from sklearn.preprocessing import OneHotEncoder import numpy as np # Reshape sizes array to 2D array sizes = np.array(sizes).reshape(-1, 1) # Initialize OneHotEncoder onehot_encoder = OneHotEncoder(sparse=False) # Fit and transform data onehot_encoded_sizes = onehot_encoder.fit_transform(sizes) # Print original and one hot encoded data print("Original sizes:", sizes.flatten()) print("One-hot encoded sizes:") for i, category in enumerate(onehot_encoder.categories_[0]): print(f"{category}: {onehot_encoded_sizes[:, i]}") |
Subscribe and Get Free Video Courses & Articles in your Email
Not the answer you re looking for? Browse other questions tagged python machine-learning one-hot-encoding label-encoding or ask your own question .