Python Introduction To Requests Library – in one of my previous articles on Python Network Programming With Urllib , we have created
some examples on urllib, So that’s it for the urllib package. As you can see, access to the standard library
is more than adequate for most HTTP tasks.
We haven’t touched upon all of its capabilities. There are numerous handler classes which we haven’t discussed, plus
the opener interface is extensible.
However, the API isn’t the most elegant, and there have been several attempts made to improve it. One of these is the very popular third-party library called Requests.
It’s available as the requests package on PyPi.
The Requests library automates and simplifies many of the tasks that we’ve been looking at. The quickest way of illustrating this is by trying some examples.
also commands for retrieving a URL with Requests are similar to retrieving a URL with the urllib package, as shown here:
|
1 2 3 4 5 6 7 8 9 10 |
import requests response = requests.get("https://codeloop.org/") print(response.status_code) print(response.reason) print(response.url) |
So this will be the result
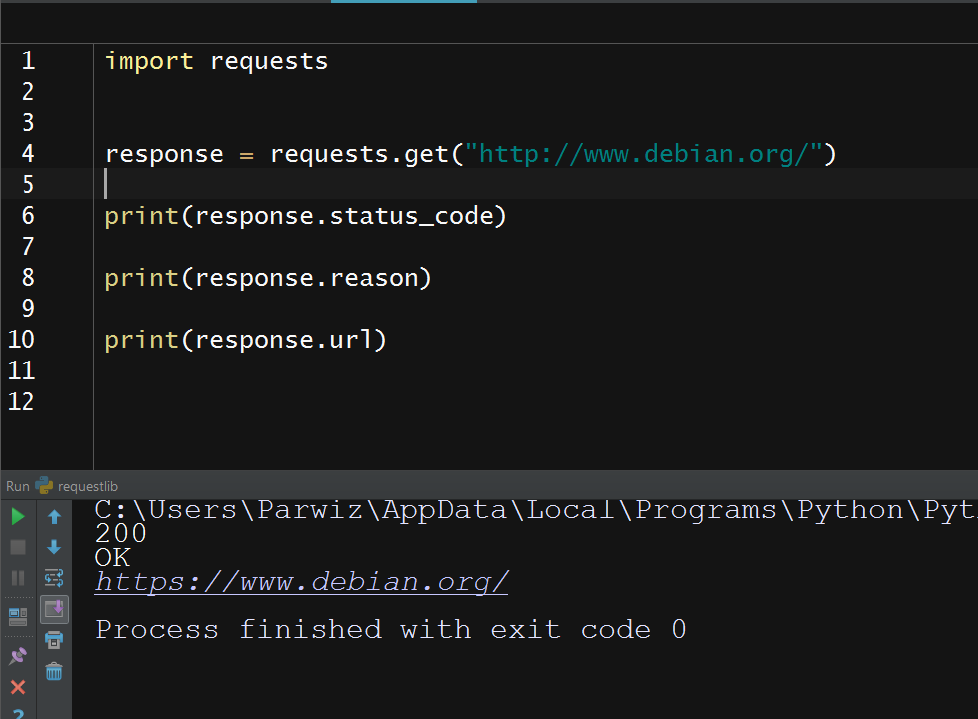
Note:
the header name in the preceding command is in lowercase. the keys in the headers attribute of Requests response objects are case insensitive.
There are some convenience attributes that have been added to the response object:
|
1 2 3 4 5 6 |
import requests response = requests.get("http://www.debian.org/") print(response.ok) print(response.is_redirect) |
So now this will be the result
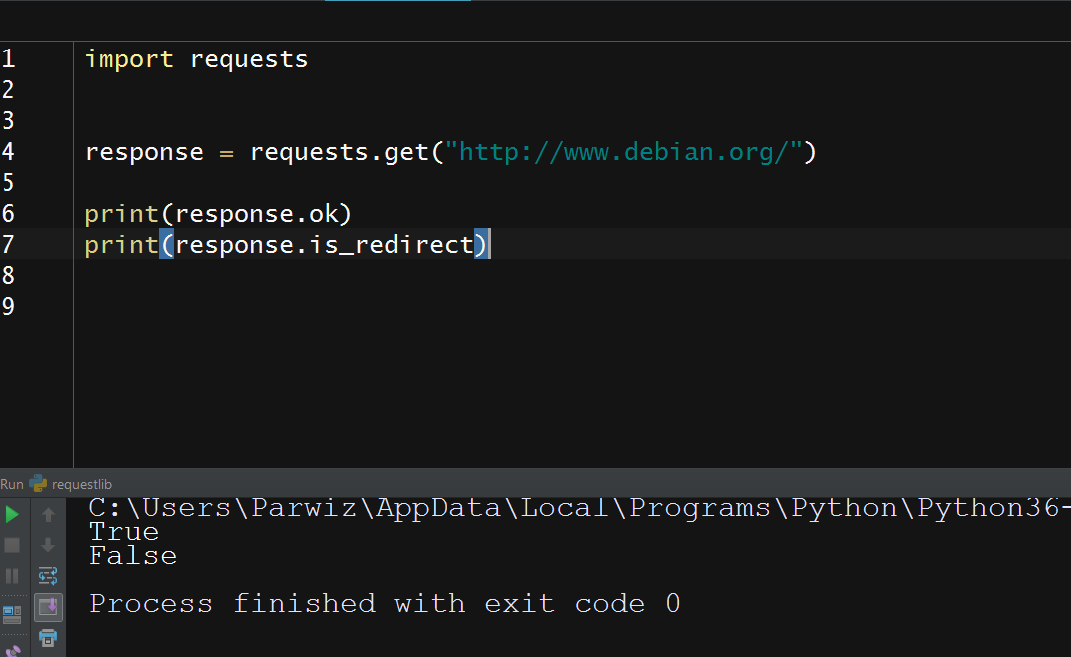
The ok attribute indicates whether the request was successful. That is, the request contained a status code in the 200 range. Also:
The is_redirect attribute indicates whether the request was redirected. We can also access the request properties through the response object:
|
1 2 3 4 5 6 |
import requests response = requests.get("http://www.debian.org/") print(response.request.headers) |
So now this is the result
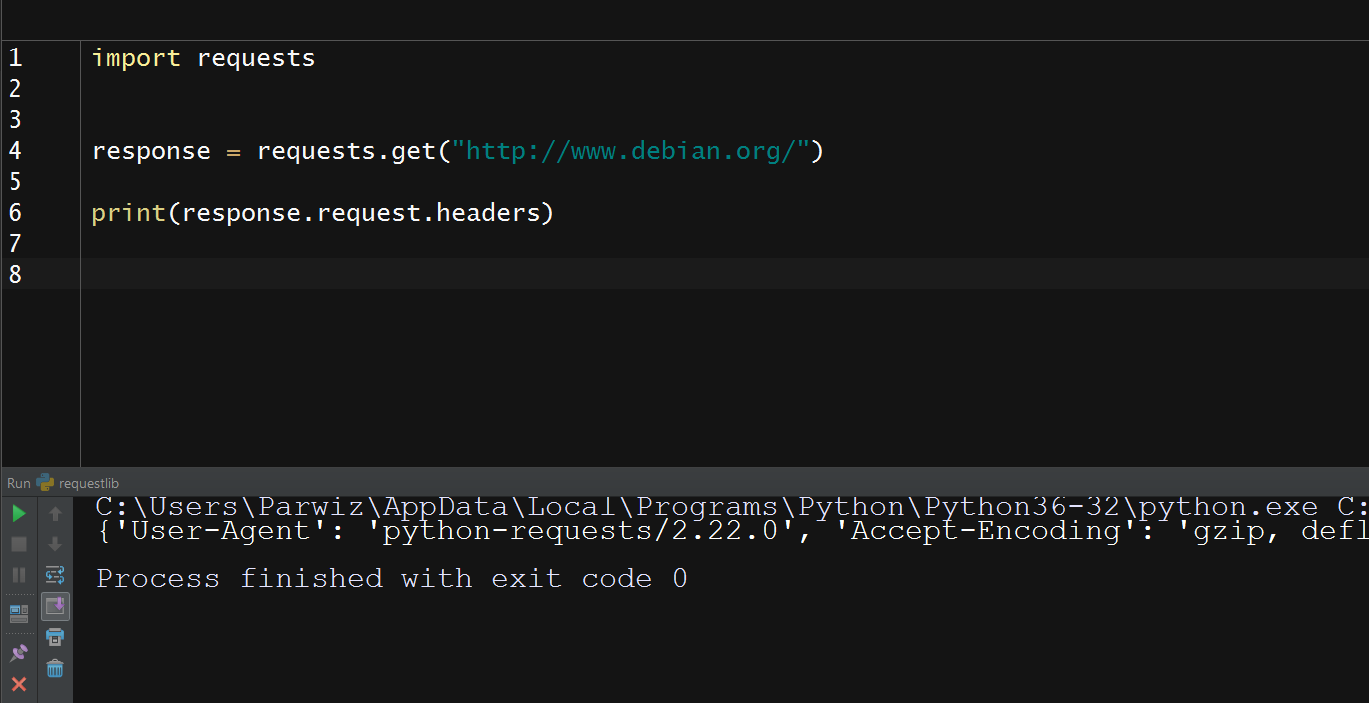
Notice that Requests is automatically handling compression for us. It’s including gzip and deflate in an Accept-Encoding header. If we look at the Content-
Encoding response, then we will see that the response was in fact gzip compressed, and Requests transparently decompressed it for us:
|
1 2 3 4 5 6 |
import requests response = requests.get("http://www.debian.org/") print(response.headers['content-encoding']) |
This will be the result
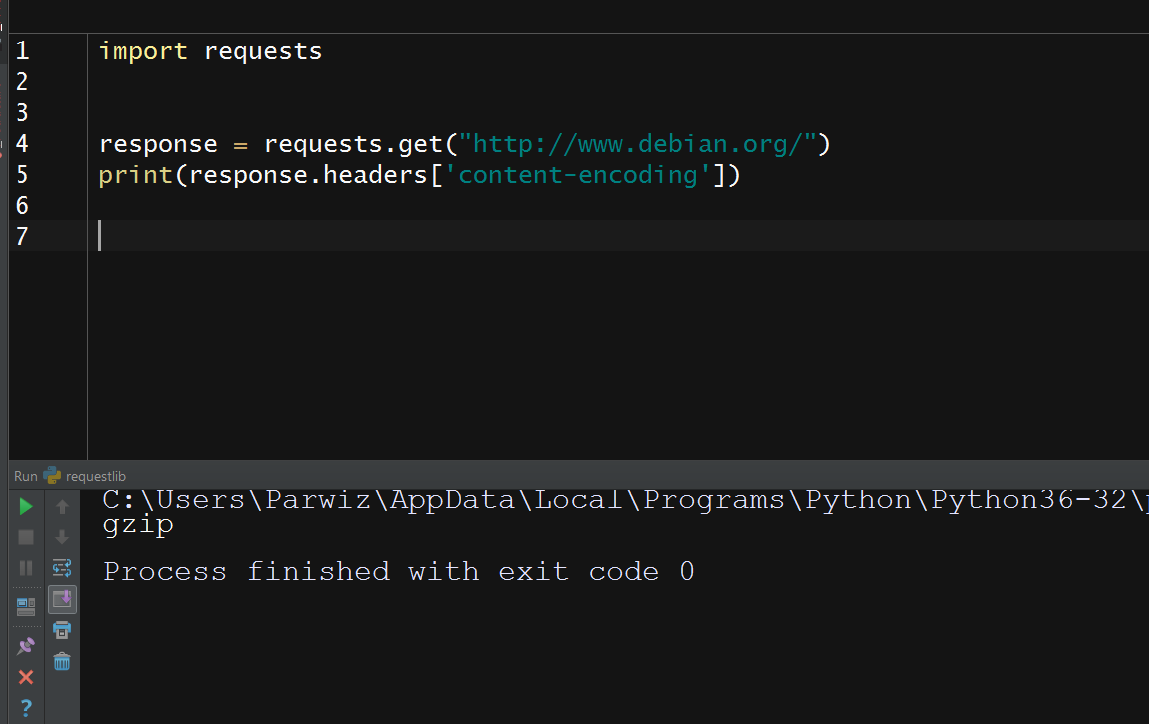
Also we can look at the response content in many more ways. To get the same bytes
object as we got from an HTTPResponse object, perform the following:
|
1 2 3 4 5 |
import requests response = requests.get("http://www.debian.org/") print(response.content) |
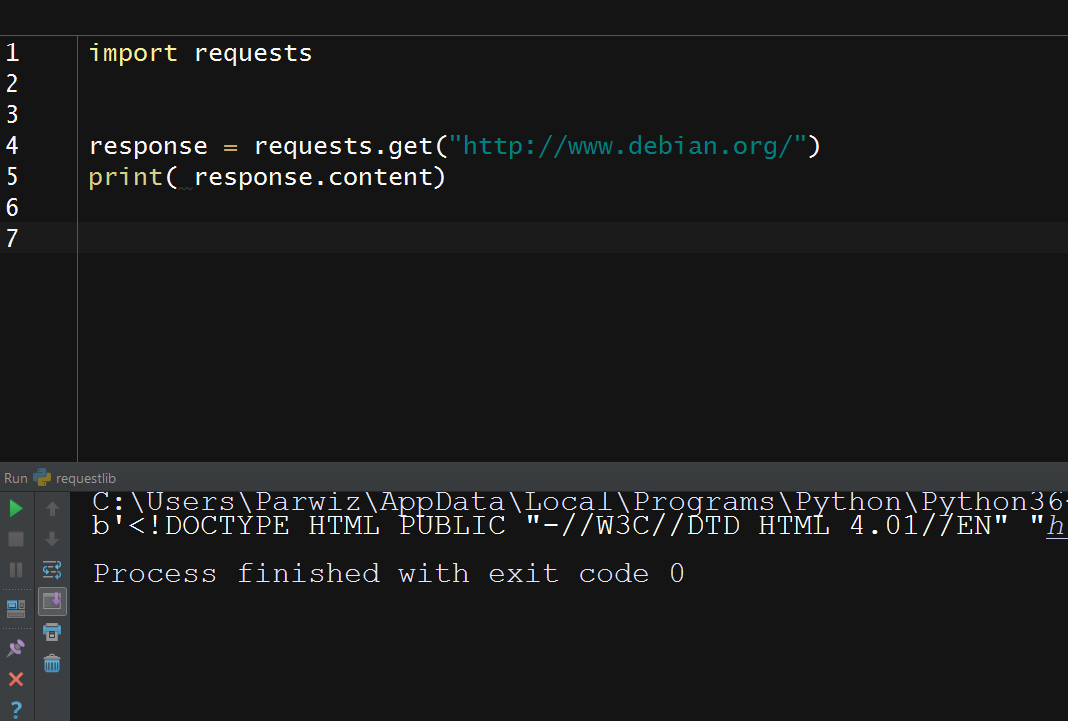
But Requests also performs automatic decoding for us. To get the decoded content,
do this:
|
1 2 3 4 5 |
import requests response = requests.get("http://www.debian.org/") print( response.text) |
So this will be the result
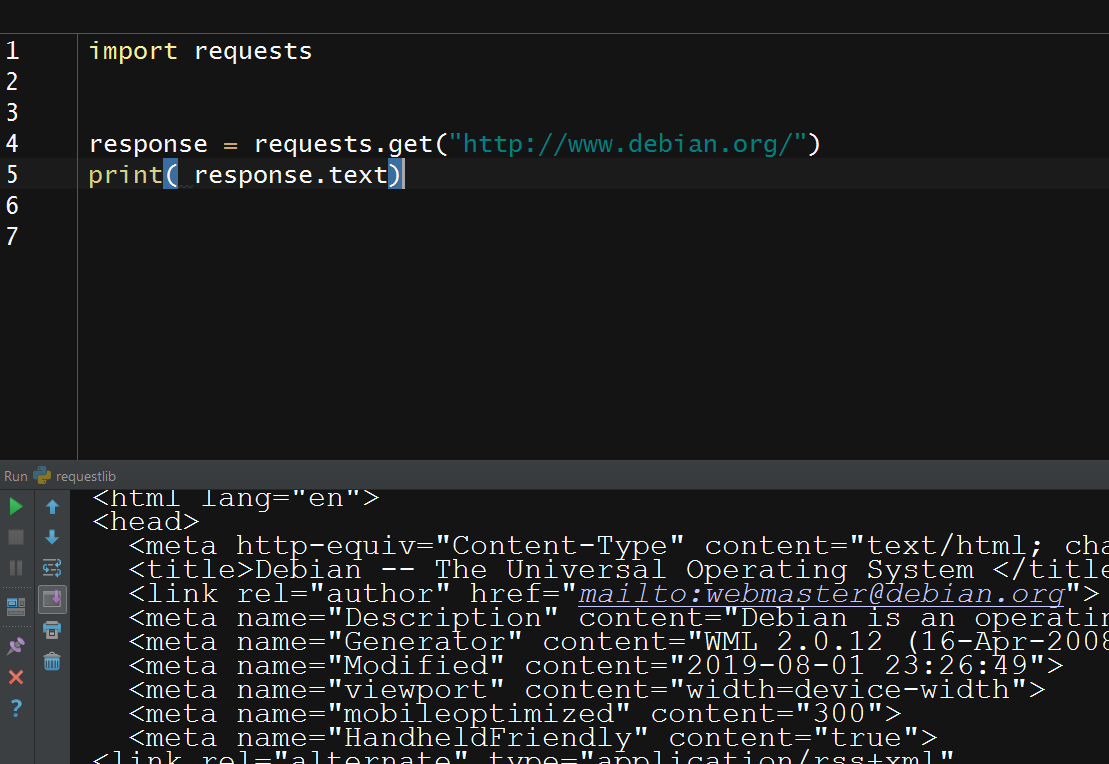
Notice:
Notice that this is now str rather than bytes. The Requests library uses values in the headers for choosing a character set and decoding the content to Unicode for
us. If it can’t get a character set from the headers, then it uses the chardet library (http://pypi.python.org/pypi/chardet) to make an estimate from the content
itself. We can see what encoding Requests has chosen here:
|
1 2 3 4 5 |
import requests response = requests.get("http://www.debian.org/") print( response.encoding) |
Handling Cookies
The Requests library automatically handles cookies. Give the following a try
|
1 2 3 4 5 |
import requests response = requests.get('http://www.github.com') print(response.cookies) |
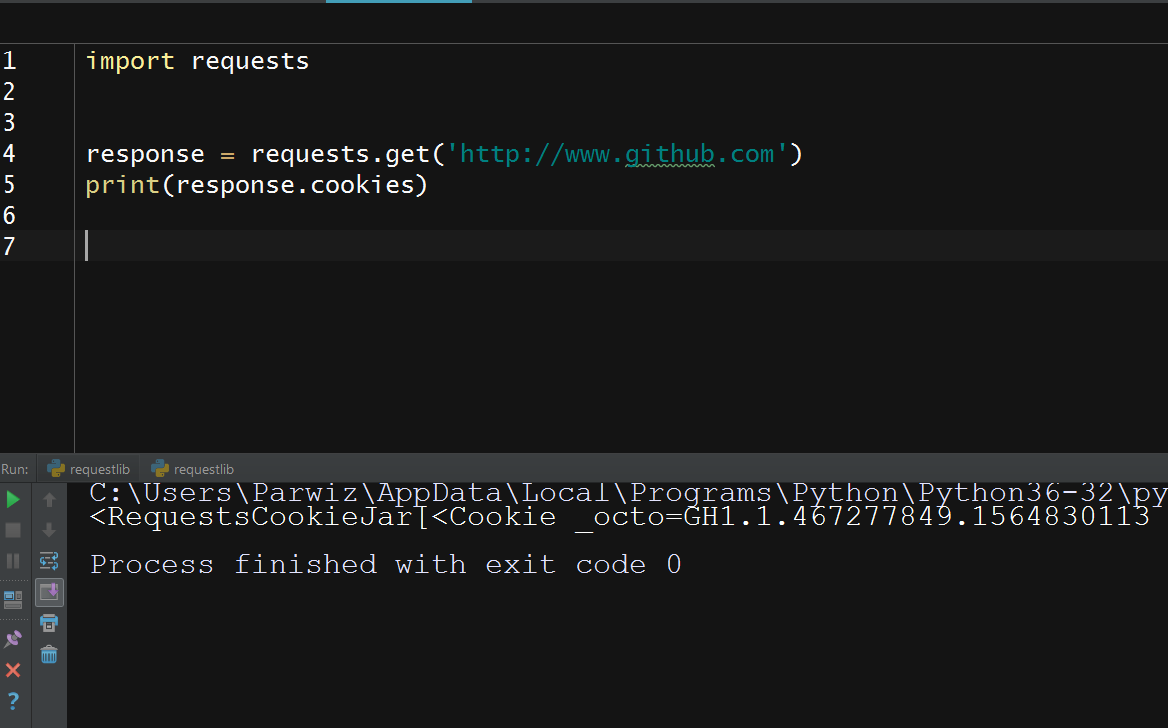
The Requests library also has a Session class, which allows the reuse of
cookies, and this is similar to using the http module’s CookieJar and the
urllib module’s HTTPCookieHandler objects. Do the following to reuse the
cookies in subsequent requests:
|
1 2 3 4 5 6 |
import requests s = requests.Session() s.get('http://www.google.com') response = s.get('http://google.com/preferences') |
The Session object has the same interface as the requests module, so we use its
get() method in the same way as we use the requests.get()method. Now, any
cookies encountered are stored in the Session object, and they will be sent with
corresponding requests when we use the get() method in the future.
Redirects are also automatically followed, in the same way as when using urllib,
and any redirected requests are captured in the history attribute.
The different HTTP methods are easily accessible, they have their own functions:
|
1 2 3 4 5 6 7 8 9 10 |
import requests s = requests.Session() s.get('http://www.google.com') response = s.get('http://google.com/preferences') print(response.status_code) print(response.text) |
So this will be the result
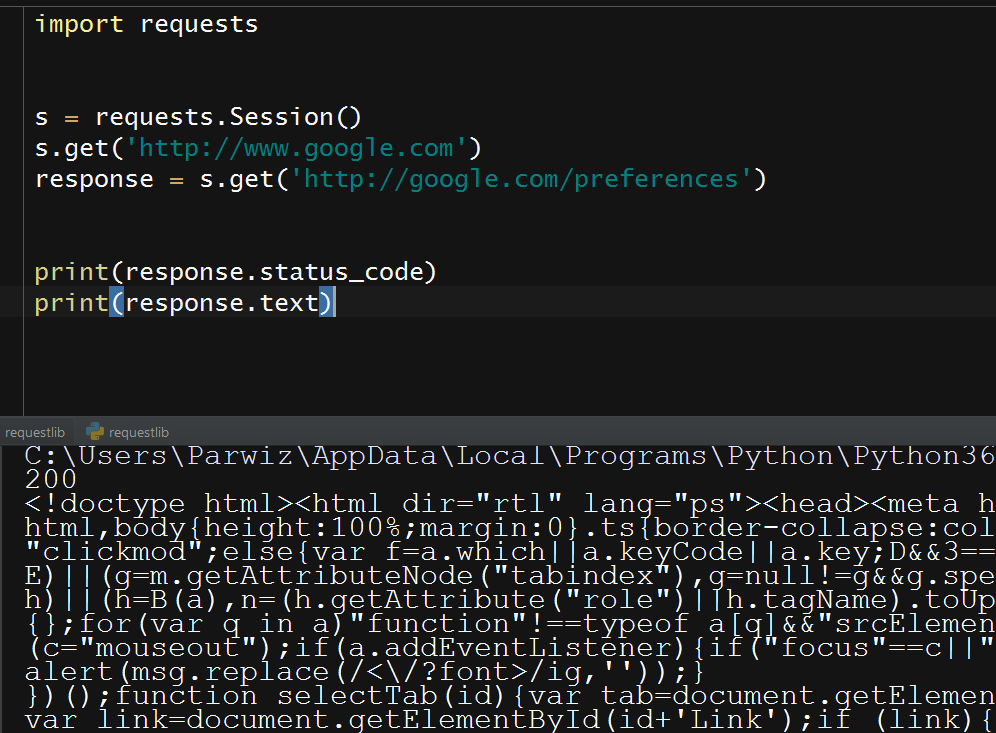
Handling Errors With Requests
Errors in Requests are handled slightly differently from how they are handled with
urllib. Let’s work through some error conditions and see how it works. Generate a
404 error by doing the following:
|
1 2 3 4 |
import requests response = requests.get('http://www.google.com/notawebpage') print(response.status_code) |
this is the result
Also you can watch the complete video for this article
Subscribe and Get Free Video Courses & Articles in your Email