Python Network Programming With Urllib : The urllib package is broken into several sub modules for dealing with the different tasks that we may
need to perform when working with HTTP. For making requests and receiving responses, we employ the urllib.request module.
Retrieving the contents of a URL is a straightforward process when done using urllib. Load your Pyhcarm IDE and do the following:
|
1 2 3 4 5 6 |
from urllib.request import urlopen response = urlopen("https://codeloop.org/") print(response) print(response.readline()) |
So after running this will be the result
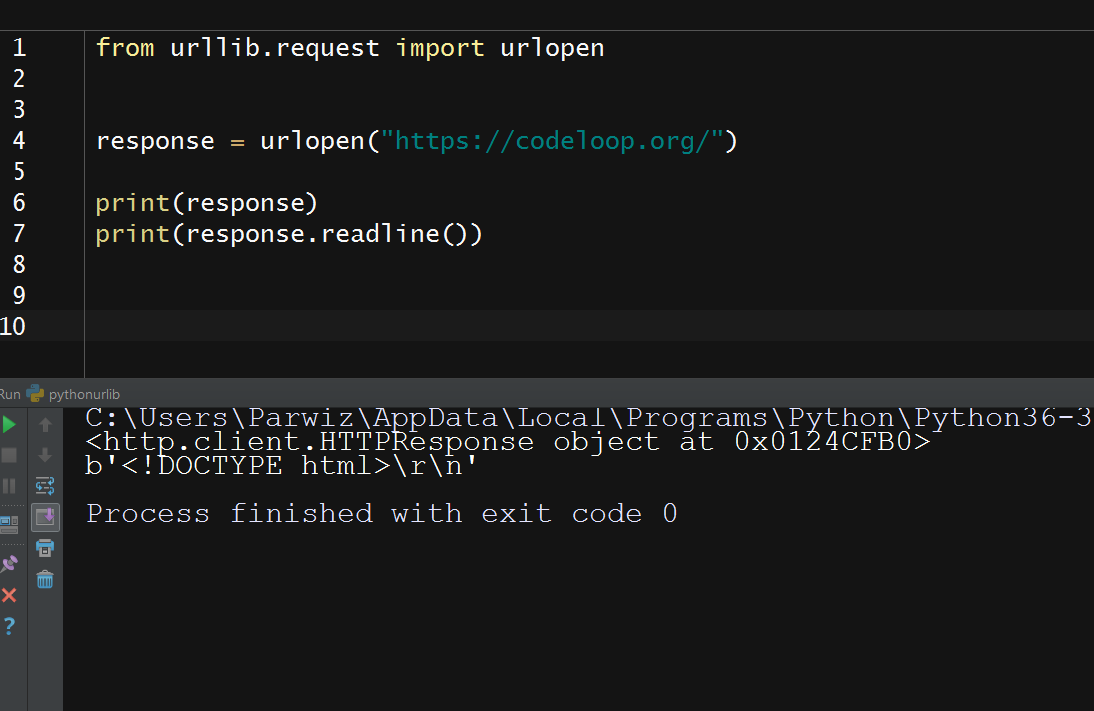
We use the urllib.request.urlopen() function for sending a request and receiving a response for the resource at https://codeloop.org/, in this case an
HTML page. We will then print out the first line of the HTML.
Response Object
Let’s take a closer look at our response object. We can see from the preceding example that urlopen() returns an http.client.HTTPResponse instance. The
response object gives us access to the data of the requested resource, and the properties and the metadata of the response. To view the URL for the response
that we received in the previous section, do this:
|
1 2 3 4 5 |
from urllib.request import urlopen response = urlopen("https://codeloop.org/") print(response.url) |
And this is the result
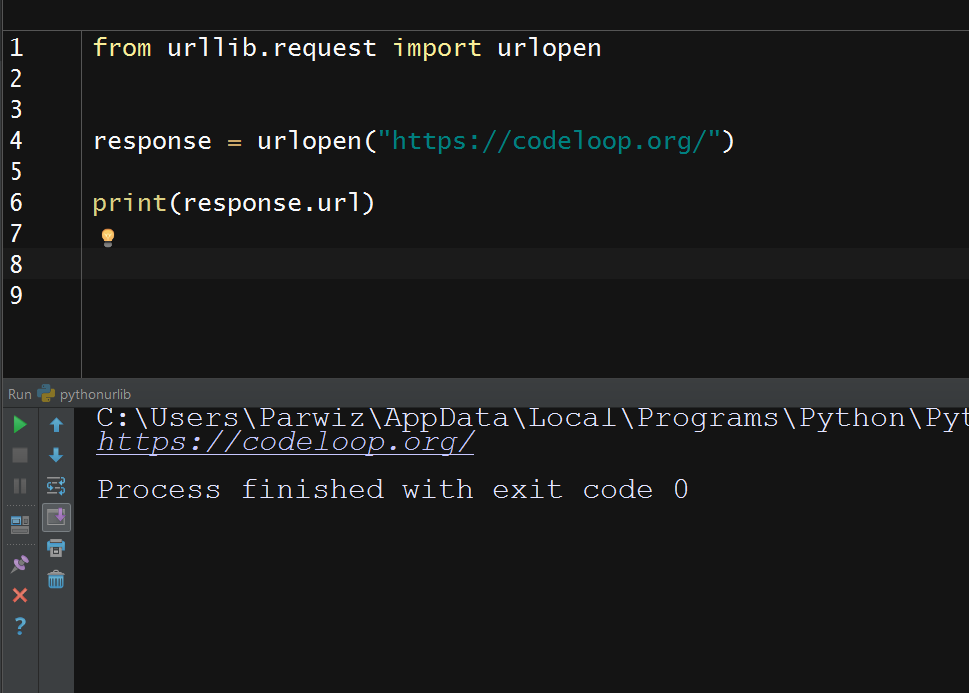
We get the data of the requested resource through a fle-like interface using the readline() and read() methods. We saw the readline() method in the previous
section. This is how we use the read() method:
|
1 2 3 4 5 |
from urllib.request import urlopen response = urlopen("https://codeloop.org/") print(response.read(100)) |
This will be the result
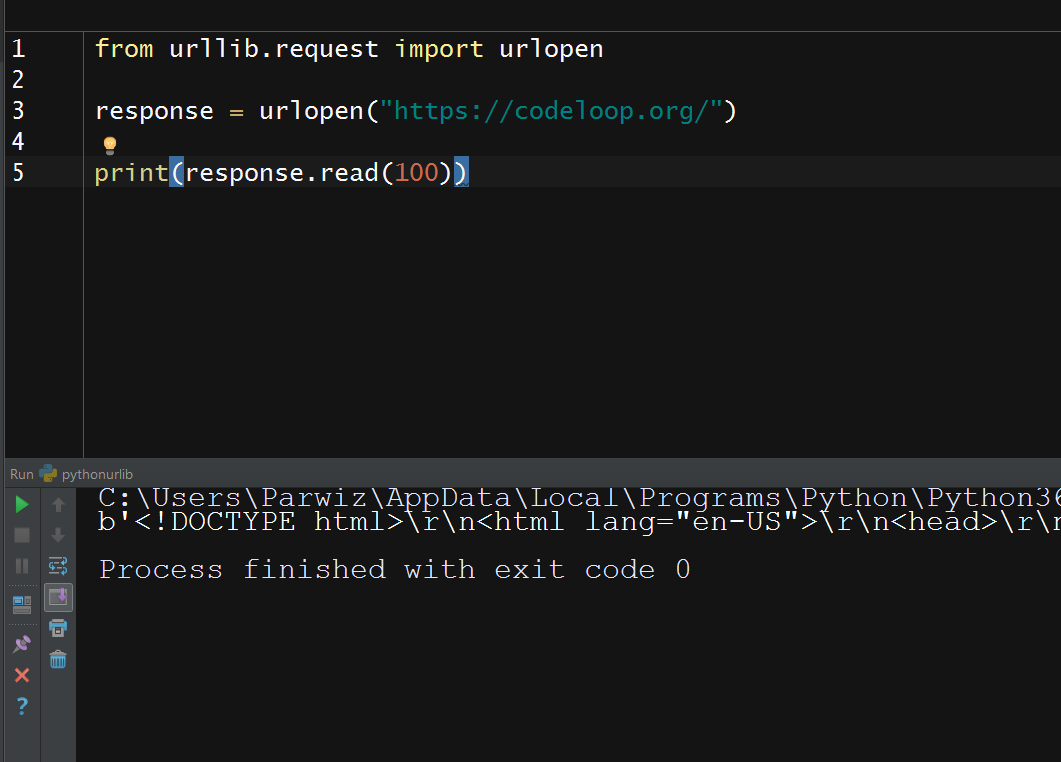
So the read() method returns the specified number of bytes from the data. Here it’s the first 50 bytes. A call to the read() method with no argument will return all the data in one go.
The file-like interface is limited. Once the data has been read, it’s not possible to go back and re-read it by using either of the aforementioned functions. To demonstrate
this, try doing the following:
Status Code:
What if we wanted to know whether anything unexpected had happened to our request? Or what if we wanted to know whether our response contained any data
before we read the data out? Maybe we’re expecting a large response, and we want to quickly see if our request has been successful without reading the whole response.
HTTP responses provide a means for us to do this through status codes. We can read the status code of a response by using its status attribute.
|
1 2 3 4 5 |
from urllib.request import urlopen response = urlopen("https://codeloop.org/") print(response.status) |
OK now this is the result
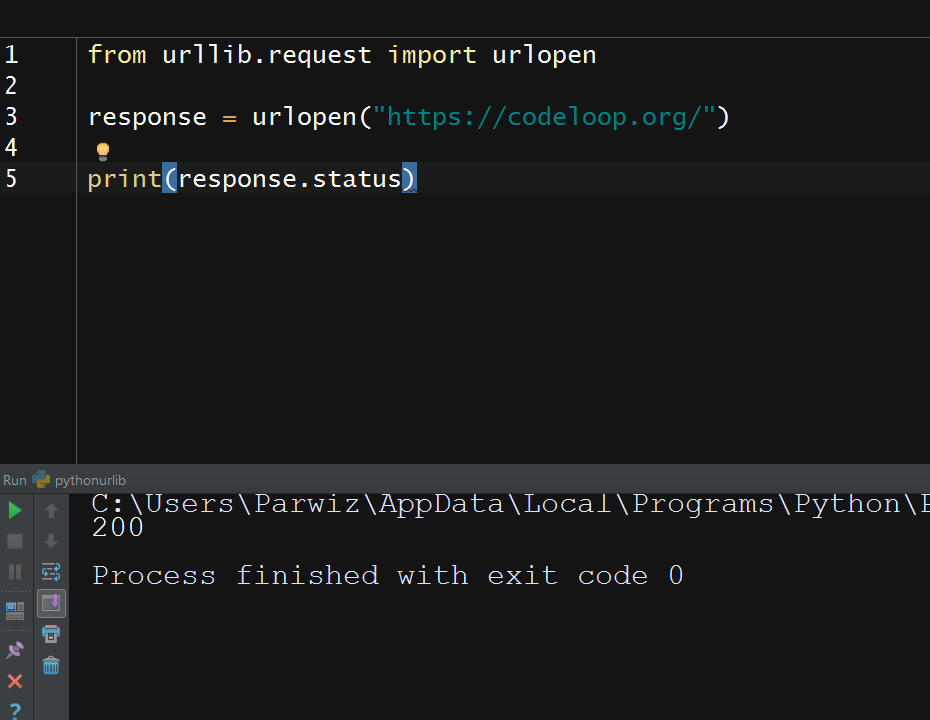
Status codes are integers that tell us how the request went. The 200 code informs us that everything went fine.
There are a number of codes, and each one conveys a different meaning. According
to their fest digit, status codes are classified into the following groups:
- Informational : 100
- Success : 200
- Redirection : 300
- Client Error : 400
- Server Error: 500
A few of the more frequently encountered codes and their messages are as follows:
- OK : 200
- Not Found : 400
- Internal Server Error : 500
Handling Problems
Status codes help us to see whether our response was successful or not. Any code in the 200 range indicates a success, whereas any code in either the 400 range or the 500
range indicates failure.Status codes should always be checked so that our program can respond
appropriately if something goes wrong. The urllib package helps us in checking the status codes by raising an exception if it encounters a problem.
Let’s go through how to catch these and handle them usefully. For this try the following command block:
|
1 2 3 4 5 6 7 8 9 10 11 |
from urllib.request import urlopen import urllib.error try: urlopen("https://codeloop.org/page") except urllib.error.HTTPError as e: print('Status : ', e.code) print("Reason : ", e.reason) print("url : ", e.url) |
After running this will be the result
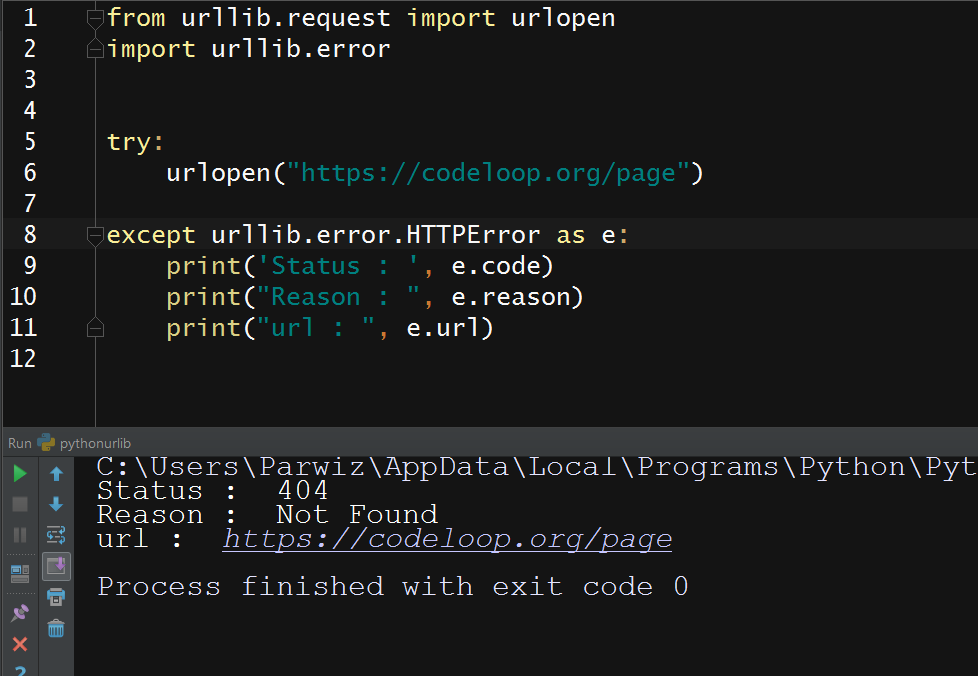
Here we’ve requested page, which doesn’t exist. So the server has returned a 404 status code, and urllib has spotted this and raised an HTTPError.
You can see that HTTPError provide useful attributes regarding the request. In the preceding example, we used the status, reason, and url attributes to get some
information about the response.
HTTP Headers
Requests, and responses are made up of two main parts, headers and a body.Headers are the lines of protocol-specific
information that appear at the beginning of the raw message that is sent over the TCP connection. The body is the rest of the message. It is separated from the headers
by a blank line. The body is optional, its presence depends on the type of request or response. Here’s an example of an HTTP request:
|
1 2 3 4 5 |
from urllib.request import urlopen response = urlopen("https://codeloop.org/") print(response.getheaders()) |
And this is the result
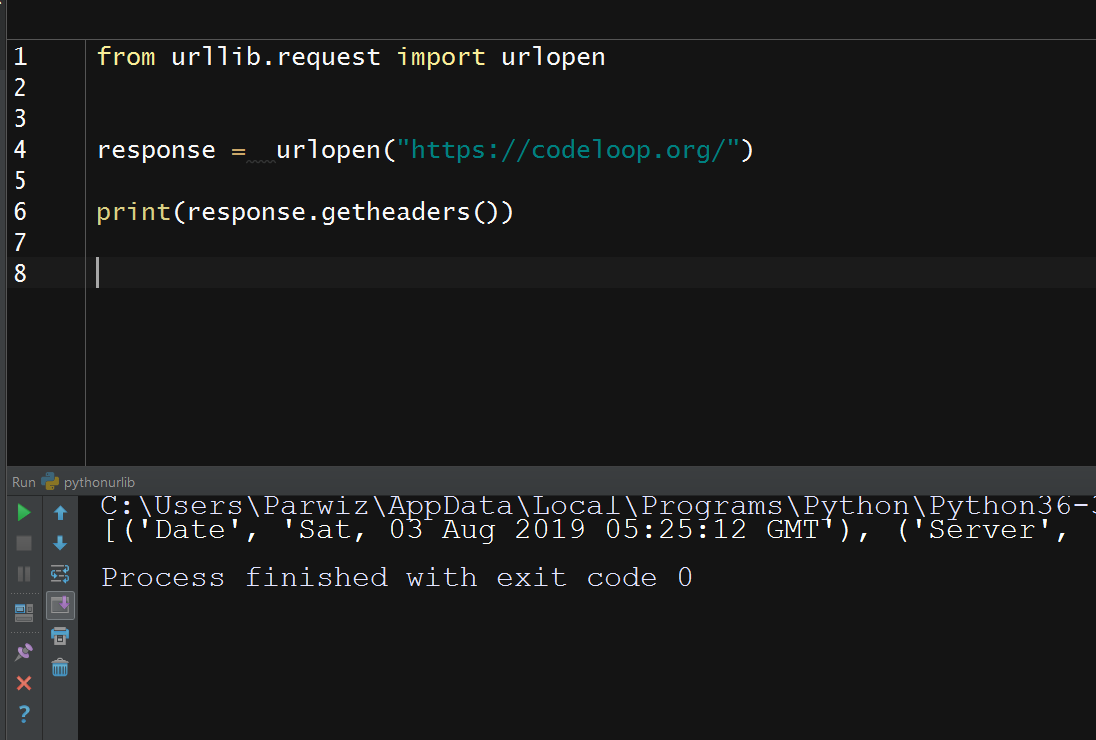
Cookies
A cookie is a small piece of data that the server sends in a Set-Cookie header as a part of the response. The client stores cookies locally and includes them in any future
requests that are sent to the server.
Servers use cookies in various ways. They can add a unique ID to them, which enables them to track a client as it accesses different areas of a site. They can store
a login token, which will automatically log the client in, even if the client leaves the site and then accesses it later. They can also be used for storing the client’s user
preferences or snippets of personalizing information, and so on.
Cookies are necessary because the server has no other way of tracking a client between requests. HTTP is called a stateless protocol. It doesn’t contain an explicit
mechanism for a server to know for sure that two requests have come from the same client. Without cookies to allow the server to add some uniquely identifying
information to the requests, things such as shopping carts (which were the original problem that cookies were developed to solve) would become impossible to build,
because the server would not be able to determine which basket goes with which request.
We may need to handle cookies in Python because without them, some sites don’t behave as expected. When using Python, we may also want to access the parts
of a site which require a login, and the login sessions are usually maintained through cookies.
Cookie Handling
We’re going to discuss how to handle cookies with urllib. First, we need to create a place for storing the cookies that the server will send us:
|
1 2 3 4 5 6 7 8 9 10 11 |
from urllib.request import build_opener, HTTPCookieProcessor from http.cookiejar import CookieJar cookie_jar = CookieJar() opener = build_opener(HTTPCookieProcessor(cookie_jar)) opener.open('http://www.github.com') print(len(cookie_jar)) |
So now this is the result
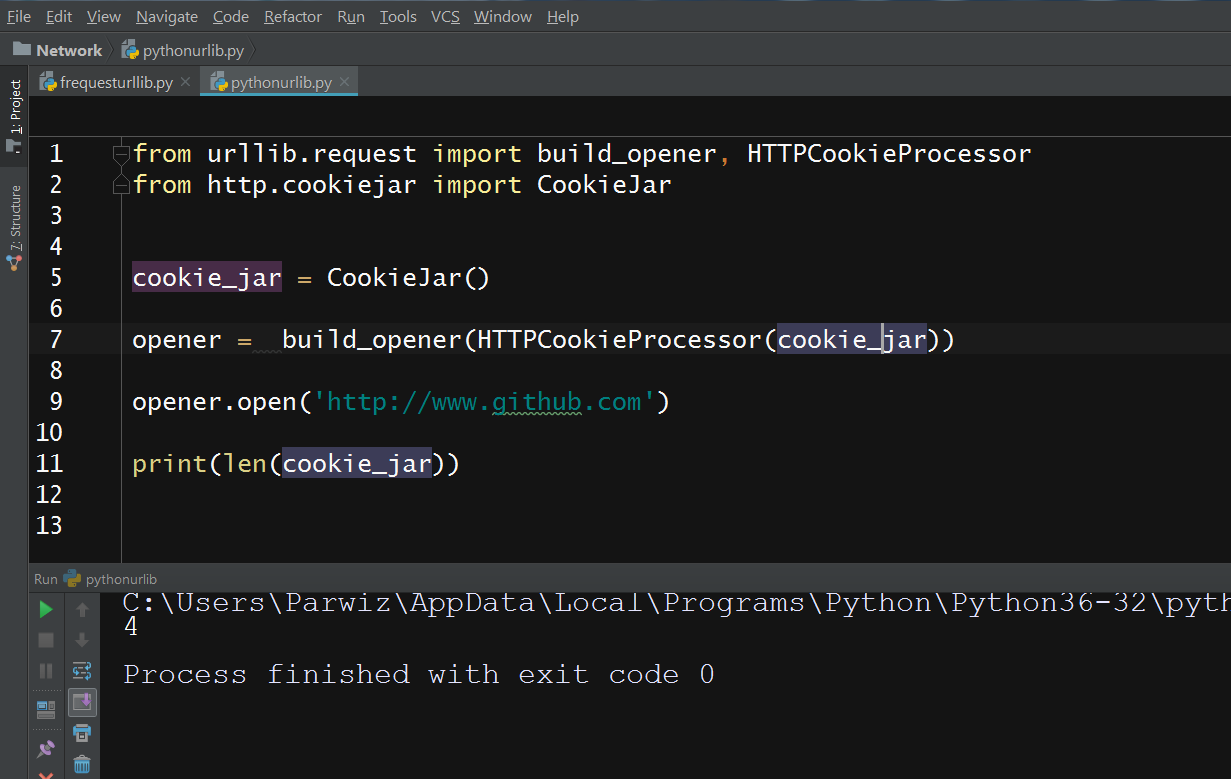
Whenever we use opener to make further requests, the HTTPCookieProcessor functionality will check our cookie_jar to see if it contains any cookies for that site
and then it will automatically add them to our requests. It will also add any further cookies that are received to the cookie jar.
The http.cookiejar module also contains a FileCookieJar class, that works in the same way as CookieJar, but it provides an additional function for easily saving the
cookies to a file. This allows persistence of cookies across Python sessions.
Know Your Cookies
It’s worth looking at the properties of cookies in more detail. Let’s examine the cookies that GitHub sent us in the preceding section
To do this, we need to pull the cookies out of the cookie jar. The CookieJar module doesn’t let us access them directly, but it supports the iterator protocol. So, a quick
way of getting them is to create a list from it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from urllib.request import build_opener, HTTPCookieProcessor from http.cookiejar import CookieJar cookie_jar = CookieJar() opener = build_opener(HTTPCookieProcessor(cookie_jar)) opener.open('http://www.github.com') cookies = list(cookie_jar) print(cookies) |
And this will be the result
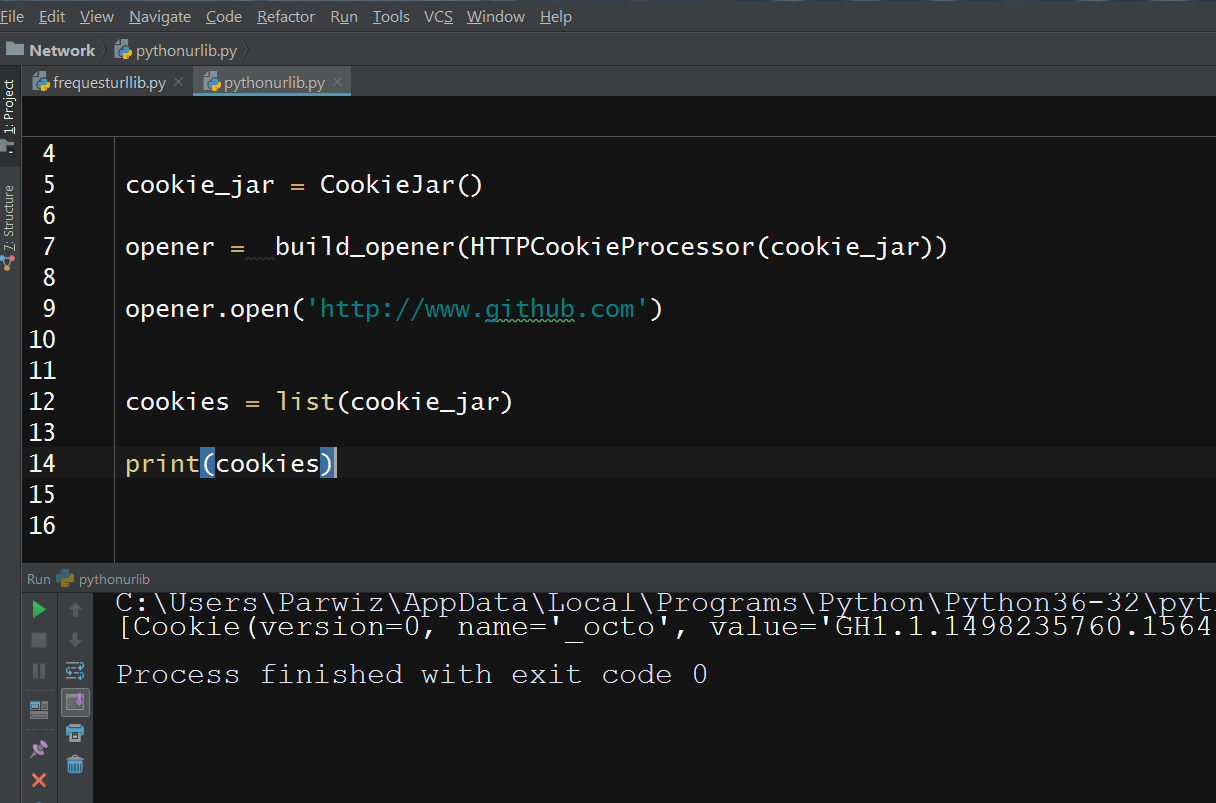
Watch the complete video for this article
Subscribe and Get Free Video Courses & Articles in your Email
