In this Python Selenium article we want to learn about Python Selenium Web Scraping, web scraping has become an essential tool for extracting valuable information from websites, Python offers several options and libraries for web scraping. One of the popular choices is Selenium, Selenium is powerful automation framework. In this article, we want to learn about scraping websites with Python and Selenium.
For working with the example of this tutorial you need some requirements, first you should have installed Python in your system, then we need to install Python Selenium and you can use pip for that like this, also you need to driver for specific browser.
|
1 |
pip install selenium |
Note: You can download the drivers from here.
This is the complete code for this article
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options options = Options() options.headless = True options.add_argument("--disable-dev-shm-usage") options.add_argument("--no-sandbox") driver = webdriver.Chrome(options=options) driver.get("http://quotes.toscrape.com/") quote_elements = driver.find_elements(By.CLASS_NAME, "quote") for quote_element in quote_elements: quote_text = quote_element.find_element(By.CLASS_NAME, "text").text author = quote_element.find_element(By.CLASS_NAME, "author").text print(f"Quote: {quote_text}") print(f"Author: {author}") print("-" * 50) driver.quit() |
First we need to import the required classes from Python Selenium
|
1 2 3 4 5 |
from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options import time |
To initiate a web driver session, we need to configure the Chrome web driver, make sure that you have already added the Chrome Driver in your working directors, We also set up a few options to run the driver in headless mode (without opening a visible browser window) and to disable unnecessary notifications.
|
1 2 3 4 5 |
options = Options() options.headless = True options.add_argument("--disable-dev-shm-usage") options.add_argument("--no-sandbox") driver = webdriver.Chrome(options=options) |
Using the get() method, we instruct the web driver to navigate to the desired URL. In our case, it’s http://quotes.toscrape.com/.
|
1 |
driver.get("http://quotes.toscrape.com/") |
Now that we have loaded the target page, we can extract specific information from it. Let’s scrape the quotes and their authors from the page. we will use Selenium find_elements() method to locate the desired elements on the page, and after that iterate over them to extract the text content.
|
1 2 3 4 5 6 7 |
quote_elements = driver.find_elements(By.CLASS_NAME, "quote") for quote_element in quote_elements: quote_text = quote_element.find_element(By.CLASS_NAME, "text").text author = quote_element.find_element(By.CLASS_NAME, "author").text print(f"Quote: {quote_text}") print(f"Author: {author}") print("-" * 50) |
After that we have finished extracting the data, it is good practice to clean up and close the web driver to release system resources.
|
1 |
driver.quit() |
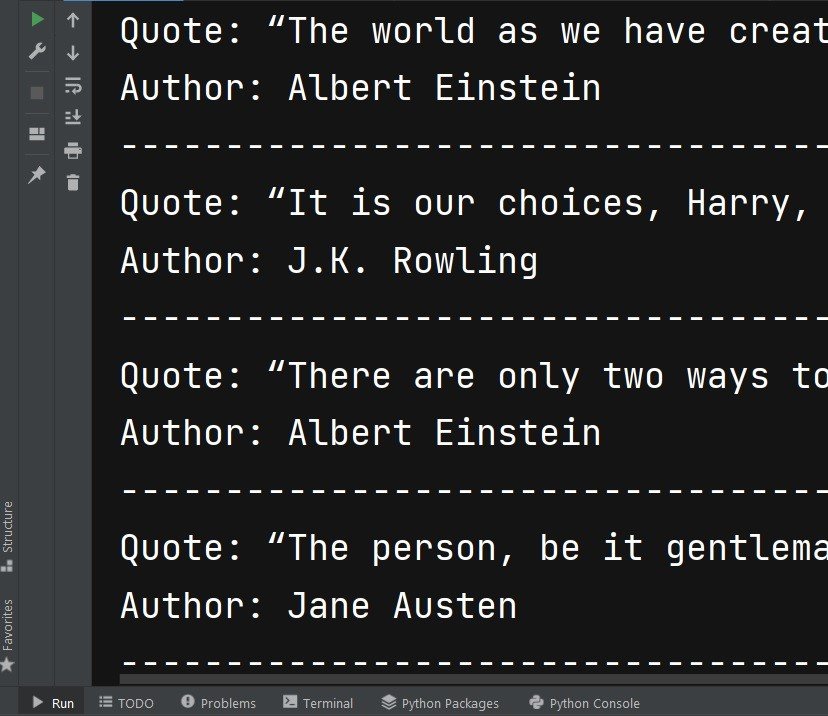
Run the code this will be the scraped data with Python Selenium
Subscribe and Get Free Video Courses & Articles in your Email