In this Python article we are Getting Started with Wikipedia API, in this topic we are going to learn how to scrap Wikipedia and retrieve information’s from Wikipedia. in this article we are going to use wikipedia library.
Wikipedia is a Python library that makes it easy to access and parse data from Wikipedia.
Search Wikipedia, get article summaries, get data like links and images from a page, and more. Wikipedia wraps the MediaWiki API so you can focus on using Wikipedia data, not getting it.
Note: this library was designed for ease of use and simplicity, not for advanced use. If you plan on doing serious scraping or automated requests, please use Pywikipediabot (or one of the other more advanced Python MediaWiki API wrappers), which has a larger API, rate limiting, and other features so we can be considerate of the MediaWiki infrastructure.
Installation
So when you want to work with wikipedia library, first of all you need to install Python Wikipedia Library. you can do this via pip.
|
1 |
pip install wikipedia |
OK now there a lot of topics in wikipedia library
Search Titles
The search() method does a Wikipedia search for a query that is supplied as an argument to it.and this method returns a list of all the article’s titles that contain the query. For example:
|
1 |
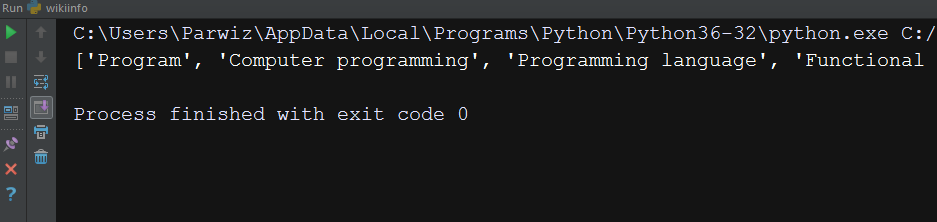
print(wikipedia.search("Programming")) |
So this will be the result
Extract Wikipedia Article Summary
We can extract the summary of a Wikipedia article using the summary() method. The article for which the summary needs to be extracted is passed as a parameter to this method.
|
1 |
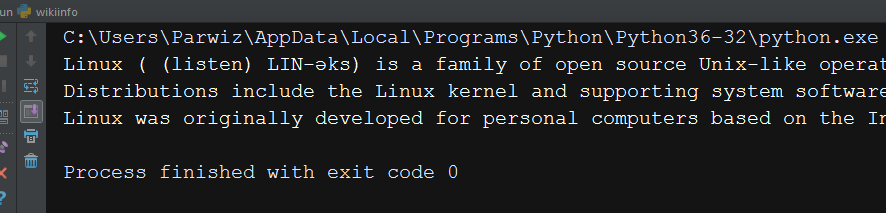
print(wikipedia.summary("Linux")) |
OK now this will be the result
The whole summary is printed in the output. We can customize the number of sentences in the summary text to be displayed by configuring the sentences argument of the method.
|
1 |
print(wikipedia.summary("Linux", sentences=3)) |
Retrieving Full Wikipedia Page Data
In order to get the contents, categories, coordinates, images, links and other metadata of a Wikipedia page, we must first get the Wikipedia page object or the page ID for the page. To do this, the page() method is used with page the title passed as an argument to the method.
|
1 |
print(wikipedia.page("Linux")) |
Extracting Metadata of a Page
To get the complete plain text content of a Wikipedia page (excluding images, tables, etc.), we can use the content attribute of the page object.
|
1 2 3 4 |
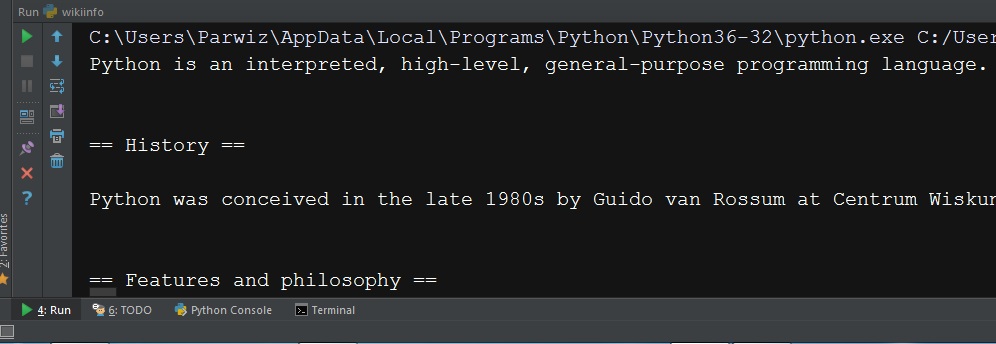
print(wikipedia.page("Python").content) print(wikipedia.page("C++").references) print(wikipedia.page("C++").title) print(wikipedia.page("C++").categories) |
So this will be the result
Also you can watch the complete video for Python Getting Started with Wikipedia API
Subscribe and Get Free Video Courses & Articles in your Email