In this Python Pandas lesson we want to learn How to Read & Write Excel Files with Python Pandas, as you know that Python is one of the best programming language, and it is used for different type of applications. One of the most popular use cases for Python is working with data, and pandas library is a powerful library for working with data in Python. Pandas can be used to read, write and manipulate data in different formats including Excel files.
Reading Excel Files with Pandas:
for reading an Excel file using Pandas, we need to install Pandas library. you can install padas using pip (pip install pandas), we can use read_excel method to read an Excel file. The read_excel method takes the path to the Excel file as its first argument.
This is an example:
|
1 2 3 4 5 6 7 |
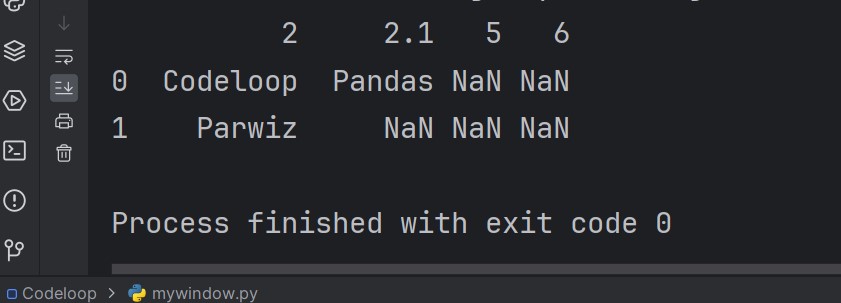
import pandas as pd # Read Excel file df = pd.read_excel('example.xlsx') # Display the data print(df.head()) |
This code reads the example.xlsx file and stores the data in a pandas DataFrame. after that the DataFrame is printed to the console using the head method, which displays the first few rows of the DataFrame.
Run the code and this will be the result
Writing Excel Files with Pandas:
Pandas can also be used to write data to an Excel file. To do this, we can use the to_excel method of a DataFrame. to_excel method takes the path to the output file as its first argument.
This is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
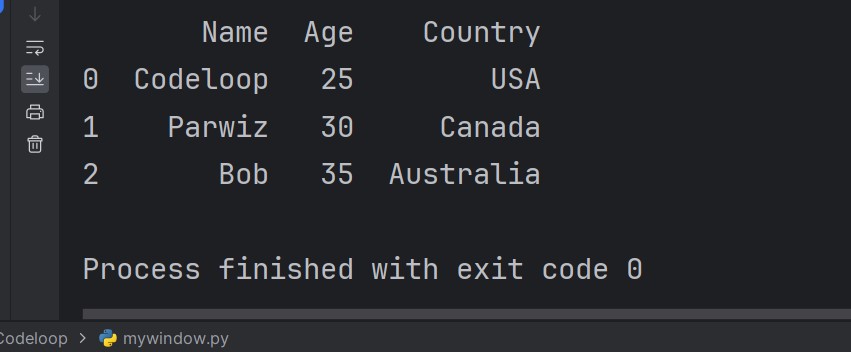
import pandas as pd # Create DataFrame data = { 'Name': ['Codeloop', 'Parwiz', 'Bob'], 'Age': [25, 30, 35], 'Country': ['USA', 'Canada', 'Australia'] } df = pd.DataFrame(data) # Write DataFrame to an Excel file df.to_excel('output.xlsx', index=False) # Confirm file was written successfully new_df = pd.read_excel('output.xlsx') print(new_df.head()) |
This code creates a DataFrame with some sample data, then uses the to_excel method to write the data to an Excel file called ‘output.xlsx’. We also confirm that the file was written successfully by reading it back in and printing the first few rows.
This will be the result
Manipulating Excel Data with Pandas
Pandas provides different data manipulation methods, and it can be used to clean and transform data in Excel files. This is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import pandas as pd # Read the Excel file df = pd.read_excel('example.xlsx') # Clean up the data df.dropna(inplace=True) # Remove rows with missing data df['Price'] = df['Price'].astype('float') df['Total'] = df['Quantity'] * df['Price'] # Write clean data to new Excel file df.to_excel('cleaned.xlsx', index=False) # Print some statistics print(df.describe()) |
This code reads an Excel file, after that cleans up the data by removing rows with missing data, and then converting the Price column to floats, and adding a new Total column. It then writes clean data to a new Excel file and prints some basic statistics about the data using the describe method.
Subscribe and Get Free Video Courses & Articles in your Email