In this Pandas article we want to learn How to Read CSV Files with Python Pandas, In the world of data analysis and manipulation, CSV files are one of the most commonly used file formats. Because they provide a simple and efficient way to store tabular data. Python Pandas library is a powerful tool for working with CSV files, because it offers different functionalities for data manipulation, analysis and visualization. In this article we want to talk how to read CSV files with Python Pandas.
How to Read CSV Files with Python Pandas
First of all we need to install Pandas library and we can use pip for that.
|
1 |
pip install pandas |
For reading a CSV file into a Pandas DataFrame, we can use read_csv() function. Let’s assume we have a file name data.csv in the same directory as our Python code. This is an example of how to read the CSV file and store it in a DataFrame:
|
1 2 3 |
import pandas as pd df = pd.read_csv('data.csv') |
After that we have our data in a DataFrame, we can explore it in different ways. Let’s take a look at some common operations.
To see the contents of the DataFrame, we can use the head() method, which displays the first few rows of the data:
|
1 |
print(df.head()) |
We can access individual columns of the DataFrame by using square brackets and specifying the column name as a string:
|
1 |
print(df['column_name']) |
To get basic statistics about the data, such as mean, median and standard deviation, we can use the describe() method:
|
1 |
print(df.describe()) |
Pandas also provides a straightforward way to write data from a DataFrame to a CSV file. We can use to_csv() function, which allows us to specify the filename and different other options.
|
1 |
df.to_csv('output.csv', index=False) |
Pandas Data Manipulation
Pandas offers powerful tools for manipulating data inside a DataFrame. Let’s explore some common operations:
We can filter data based on certain conditions using boolean indexing. For example, let’s filter the DataFrame to only include rows where the age column is greater than 30:
|
1 |
filtered_data = df[df['age'] > 30] |
We can add a new column to the DataFrame by simply assigning a value to it. For example, let’s add a column named income that contains random income values:
|
1 2 3 |
import numpy as np df['income'] = np.random.randint(1000, 5000, len(df)) |
Pandas allows us to perform different aggregations on the data, such as sum, mean, count, etc. Let’s calculate the average income based on gender:
|
1 |
average_income = df.groupby('gender')['income'].mean() |
This is the complete code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import pandas as pd import numpy as np # Reading a CSV File df = pd.read_csv('data.csv') # Displaying Data print(df.head()) # Accessing Columns print(df['age']) # Basic Statistics print(df.describe()) # Writing to a CSV File df.to_csv('output.csv', index=False) # Data Manipulation # Filtering Data filtered_data = df[df['age'] > 30] # Adding a New Column df['income'] = np.random.randint(1000, 5000, len(df)) # Aggregating Data average_income = df.groupby('gender')['income'].mean() |
And this is our data.csv file
|
1 2 3 4 5 6 |
name,age,gender John,25,Male Codeloop,32,Female Doe,45,Male Sophia,28,Female David,36,Male |
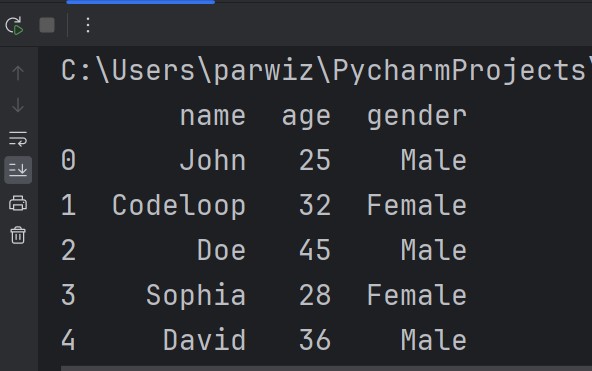
This will be the output
More Articles on Python Pandas
Subscribe and Get Free Video Courses & Articles in your Email